Absolute Loss Machine Learning
The Brier score loss function is L_by_is y_i - s2 and the absolute loss function is L_ay_is y_i - s. We all use machine learning algorithms to solve various complex problems and select them based on the loss function value and evaluation metrics.
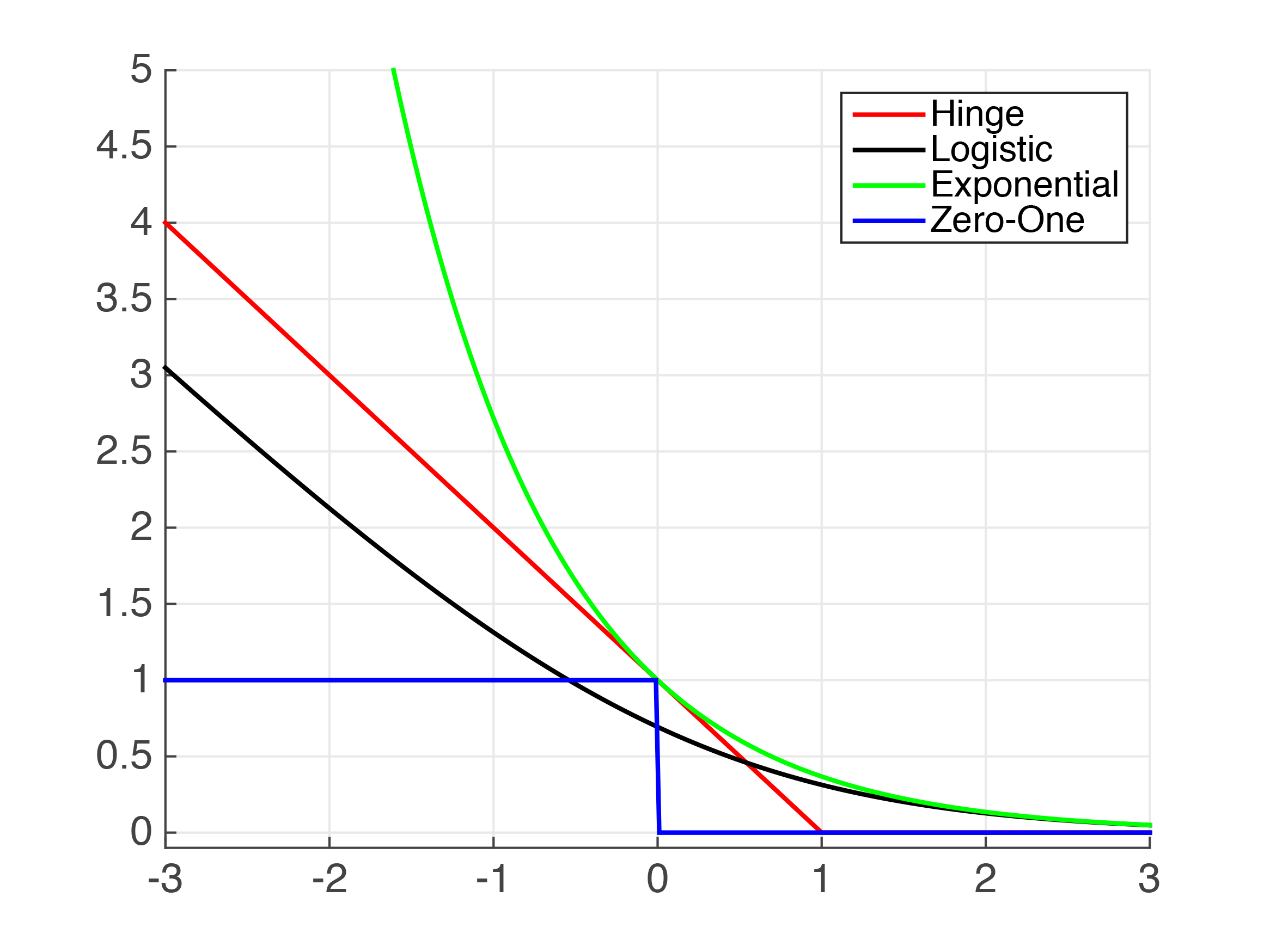
10 Empirical Risk Minimization
As An Error Function L1-norm loss function is also known as least absolute deviations LAD least absolute errors LAE.
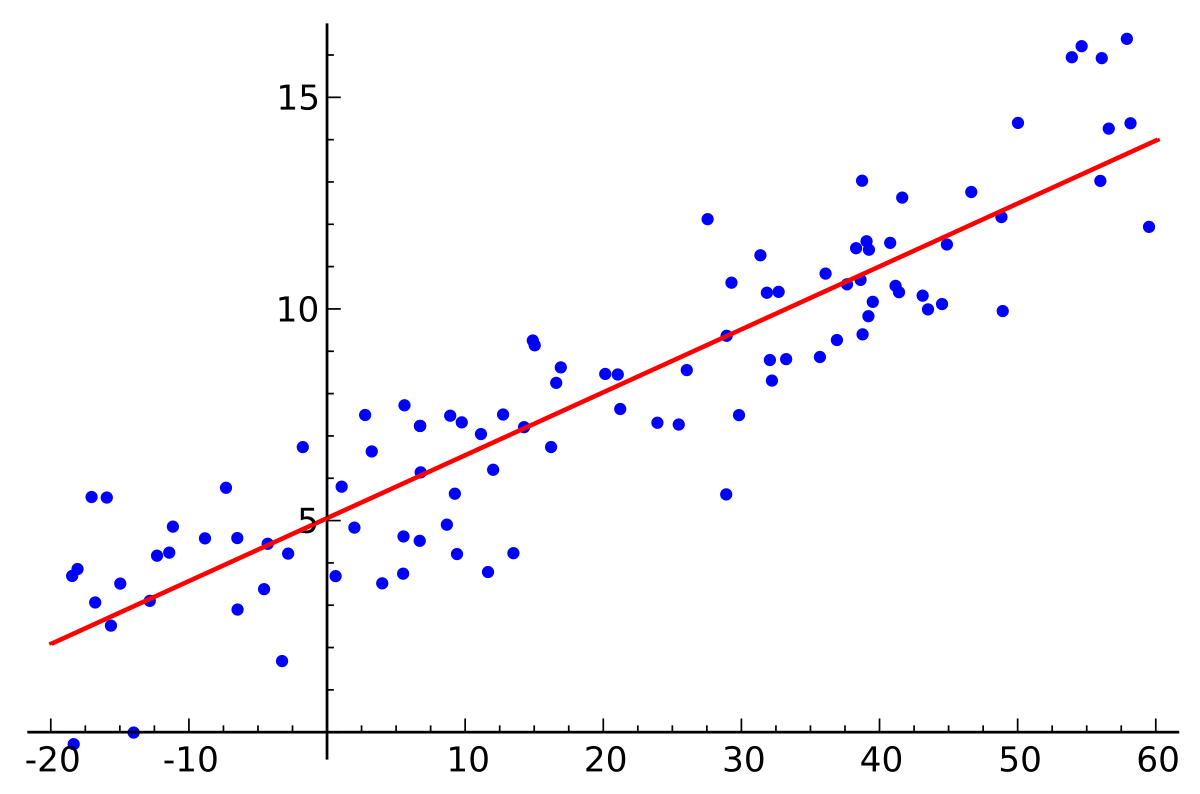
Absolute loss machine learning. And 2 L1-regularization vs L2-regularization. While practicing machine learning you may have come upon a choice of the mysterious L1 vs L2. An optimization problem seeks to minimize a loss function.
I came across the statement that if someone uses the absolute loss function as the loss of a regression model then there is no simple closed form solution for the problem I suppose the problem being to minimise the loss. If predictions deviates too much from actual results loss function would cough up a very large number. Typically in machine learning problems we seek to minimize the error between the predicted value vs the actual value.
This should be done carefully however as convergence issues may appear. Mainly the loss functions are divided into three categories. If the loss is calculated for a single training example it is called loss or error function.
Loss Function For Regression Problem in Machine Learning Python Implementation Using Numpy and Tensorflow. The loss function is a method of evaluating how well specific algorithms are predicting the correct outcome. Gradually with the help of some optimization function loss function learns to reduce the error in prediction.
The following three options arises. Thus Machines essentially learn by means of a loss function. Browse other questions tagged absolute-value machine-learning regression or ask your own question.
In Machine learning the loss function is determined as the difference between the actual output and the predicted output from the model for the single training example while the average of the loss function for all the training example is termed as the cost function. This computed difference from the loss functions such as Regression Loss Binary Classification and Multiclass Classification loss. Mean Squared Logarithmic Error.
But do we know that we are selecting the correct loss function for our algorithm. A loss function has an expected loss E_YLYs Rps. The data points that are too large or too small than the mean.
An objective function is either a loss function or its negative in which case it is to be maximized. MAE loss is also categorized in the regression problem MAE loss calculates the average of absolute differences between the actual value and predicted values when our data includes outliers we use MAE so what are outliers. A loss function is a proper score rule if the expected loss Rps is minimized with respect to s by setting sp for any pin01.
In a project if real outcomes deviate from the projections then comes the loss function that will cough up a very large amount. Introduction By means of the loss function machines learn. Name a few.
1 L1-norm vs L2-norm loss function. Mean Absolute Error MAE Loss. While more commonly used in regression the square loss function can be re-written and utilized for classification.
In statistics typically a loss. If not then lets find out. Its a method of evaluating how well specific algorithm models the given data.
If the outliers are not. Machines learn by means of a loss function. In mathematical optimization and decision theory a loss function or cost function is a function that maps an event or values of one or more variables onto a real number intuitively representing some cost associated with the event.
The fastest approach is to use MAE. The most accurate approach is to apply the Huber loss function and tune its hyperparameter δ. Log loss focal loss exponential loss hinge loss relative entropy loss and other.
Usually the two decisions are. Huber Loss or Smooth Mean Absolute Error. It is a method of determining how well the particular algorithm models the given data.
The word loss or error represents the penalty for failing to achieve the expected output.
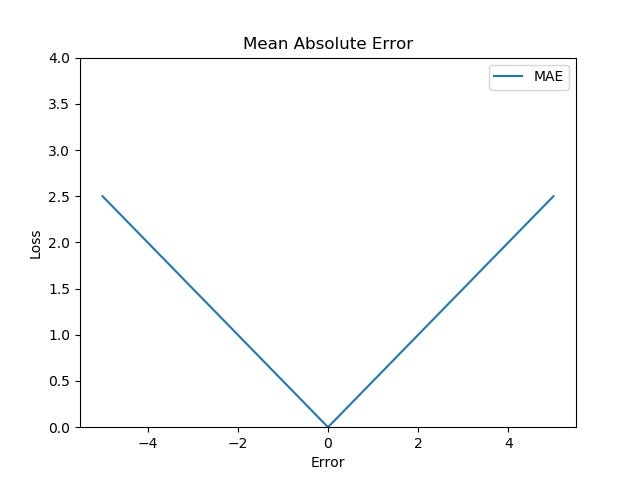
A Comprehensive Guide To Loss Functions Part 1 Regression By Rohan Hirekerur Analytics Vidhya Medium

Introduction To Loss Functions

Loss Functions And Optimization Algorithms Demystified By Apoorva Agrawal Data Science Group Iitr Medium

What Are The Impacts Of Choosing Different Loss Functions In Classification To Approximate 0 1 Loss Cross Validated
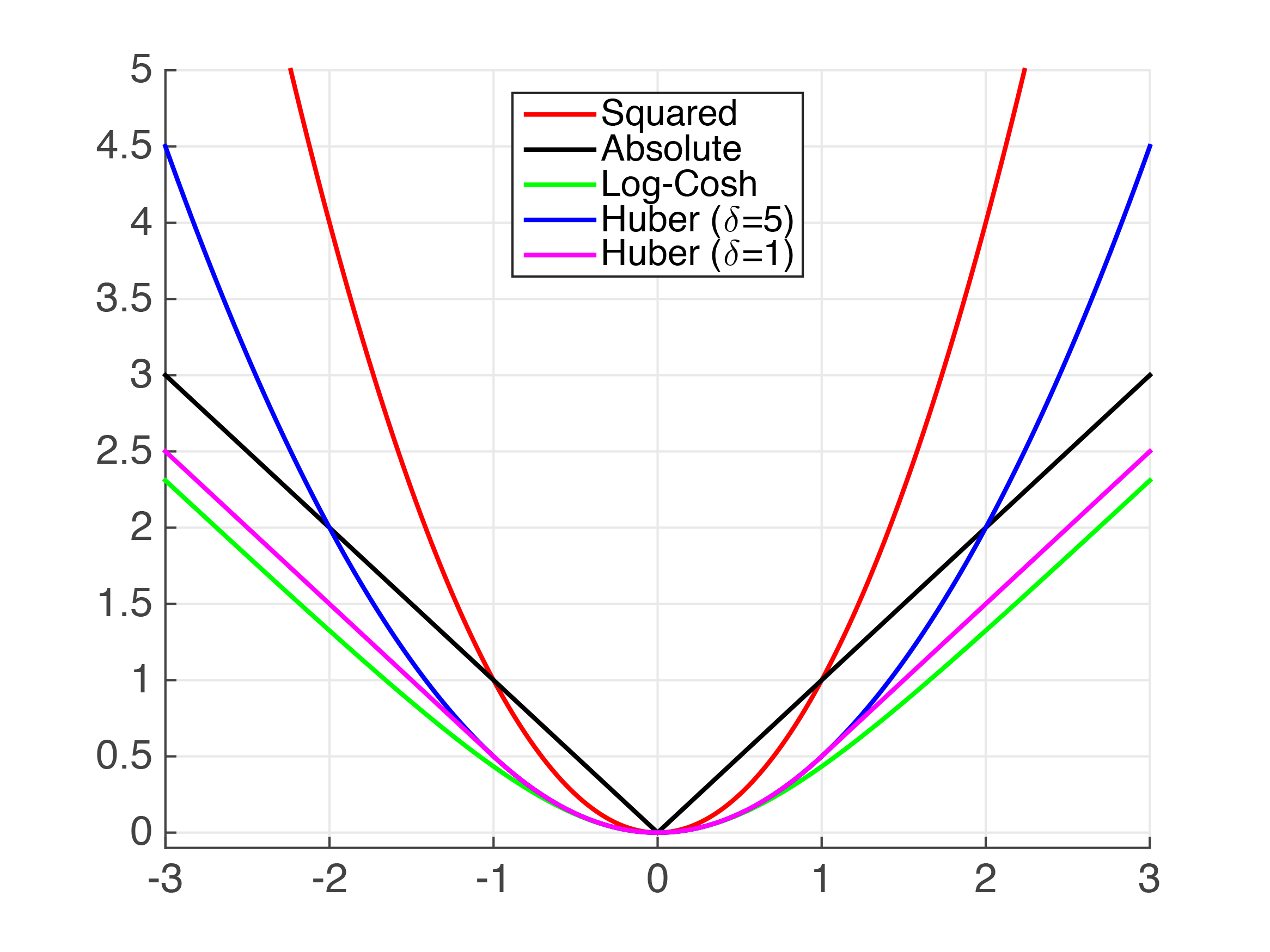
10 Empirical Risk Minimization

Interpreting Loss Curves Testing And Debugging In Machine Learning

Introduction To Loss Functions

Understanding The 3 Most Common Loss Functions For Machine Learning Regression By George Seif Towards Data Science
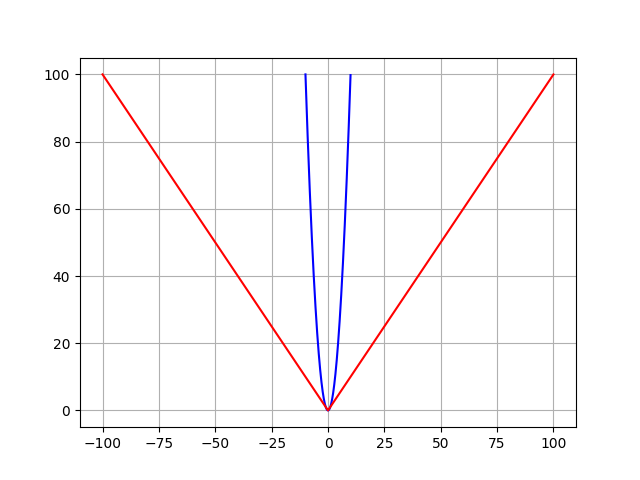
Understanding The 3 Most Common Loss Functions For Machine Learning Regression By George Seif Towards Data Science
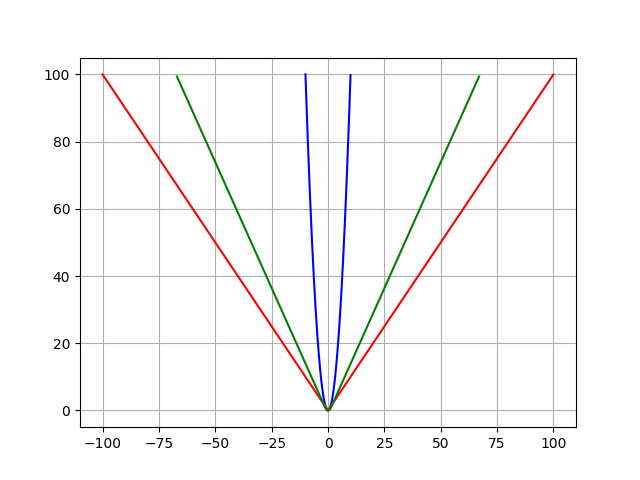
Understanding The 3 Most Common Loss Functions For Machine Learning Regression By George Seif Towards Data Science
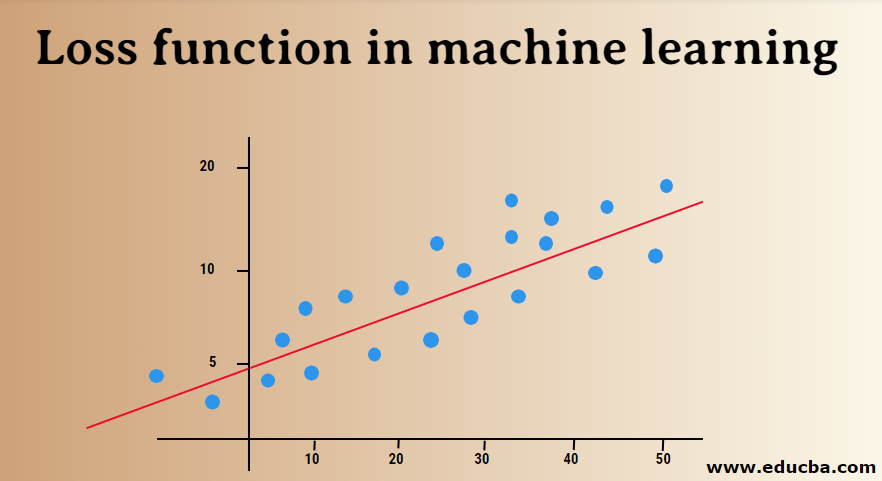
Loss Functions In Machine Learning Working Different Types
Loss Function Loss Function In Machine Learning
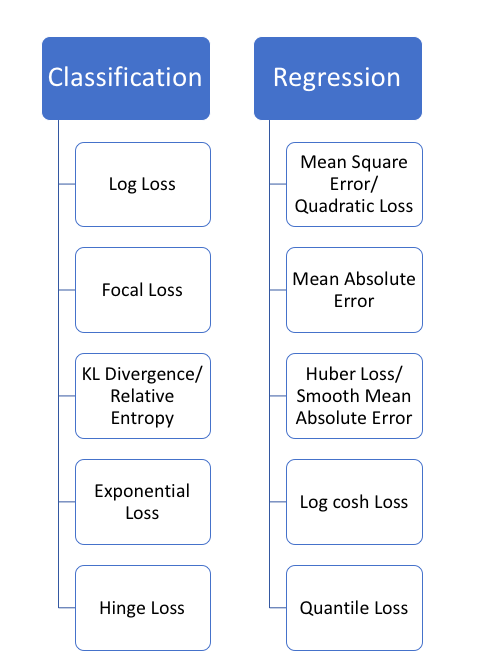
5 Regression Loss Functions All Machine Learners Should Know By Prince Grover Heartbeat
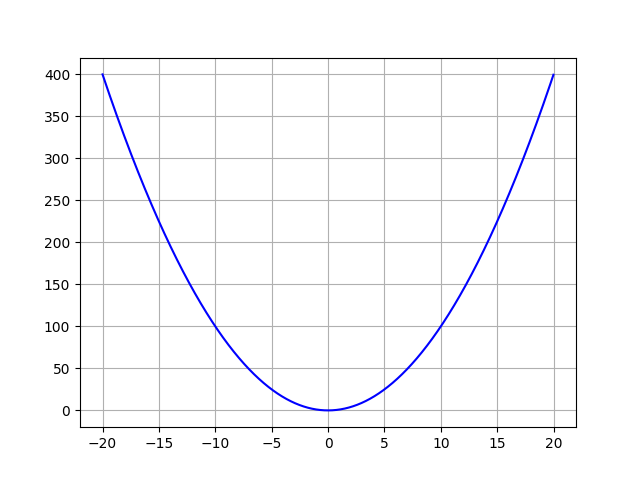
Understanding The 3 Most Common Loss Functions For Machine Learning Regression By George Seif Towards Data Science

Understanding Loss Functions In Machine Learning Engineering Education Enged Program Section

The Professionals Point Loss Functions In Machine Learning Mae Mse Rmse
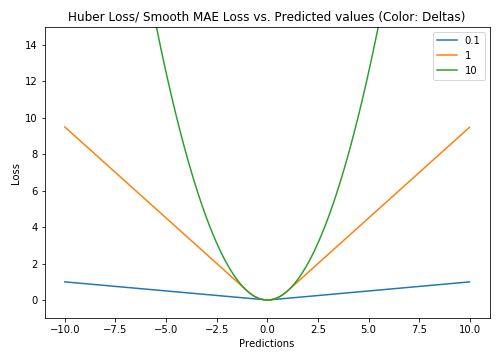
5 Regression Loss Functions All Machine Learners Should Know By Prince Grover Heartbeat
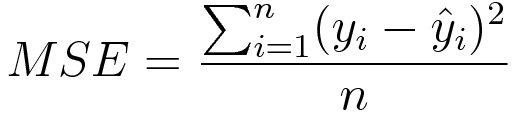
Common Loss Functions In Machine Learning By Ravindra Parmar Towards Data Science

5 Regression Loss Functions All Machine Learners Should Know By Prince Grover Heartbeat
{kind=link}
Post a Comment for "Absolute Loss Machine Learning"